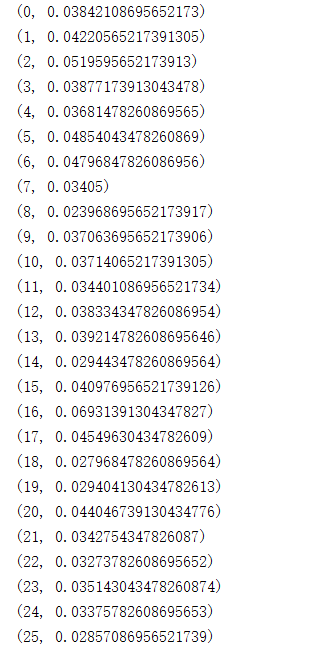
import string def findstr(str1,str2): a = 0 r = [] while a < len(str1): a = word.find(str2, a) if a == -1: break r.append(a) a = a + 1 x = 0 while x + 1 <len(r): print(r[x + 1] - r[x]) x = x + 1 word = "密文段落" findstr(word,'sxc')
#重合指数算法,str为文本,n为假设的秘钥长度,可以分别1-n密钥长度下的ic值,找到峰值ic对应的n的大小 def count_IOC(str,n): x = 0 r = [] ic_all = [] while x < n: sum_all = 0 c = str[x::n] len_str = len(c) for y in range(0,26): r.append(c.count(chr(97+y) ,0,len_str)) for p in range(0,26): sum_all = sum_all + r[p] * (r[p] - 1) ic = float(sum_all)/(len_str * (len_str - 1)) print(ic) ic_all.append(ic) x = x + 1 return sum(ic_all)/ n #假设猜测秘钥长度在10以下 for x in range(0,10): count_IOC(word, x)
结果如下,峰值为n = 7时,佐证了用kasiski测试法算出的秘钥等于7.
知道了密钥,下一步就是利用拟重合指数测试法了。
首先按照已知秘钥的长度,将密文7个一行7各一行进行分组,把每列作为一组进行分组,
1 2 3 4
#对密文进行分组(密文文本,第i组,秘钥长度) def divstr(str, i, n): c = str[i::n] return c
#所有成员自增 def member_plus(r): m = [] for i in r: if i == 'z': i = chr(96) m.append(chr(ord(i)+1)) return ('').join(m) 这里有必要说一下return('').join(p),p是一个list,而我们需要的是个字符串,如果返回list,下边就会报错,因为python中有list.count(ord)和str.count(sub,,)函数。
#拟重合指数 def count_NIOC(i, c): p = [0.08167, 0.01492, 0.02782, 0.04253, 0.12702, 0.02228, 0.02015, 0.06094, 0.06966, 0.00153, 0.00772, 0.04025, 0.02406, 0.06749, 0.07507, 0.01929, 0.00095, 0.05987, 0.06327, 0.09056, 0.02758, 0.00978, 0.02360, 0.00150, 0.01974, 0.00074] len_str = len(c) r = [] sum_m = 0 for y in range(0, 26): r.append(c.count(chr(97 + y), 0, len_str))#统计字串中a-z的数量 for x in range(0, 26): f = (r[x] * p[x]) / len_str sum_m = sum_m + f print(i,sum_m)
#改变第二个参数:第几组子密文段,第三个参数:秘钥长度,分别计算秘钥中的各个字母 str0 = divstr(word,2,7) for x in range(0,26): count_NIOC(x, str0) str0 = member_plus(str0)#每计算一次Mx,子密文段自加

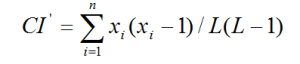
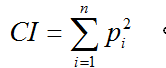

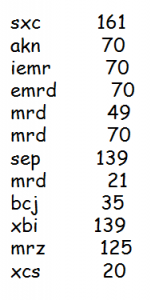
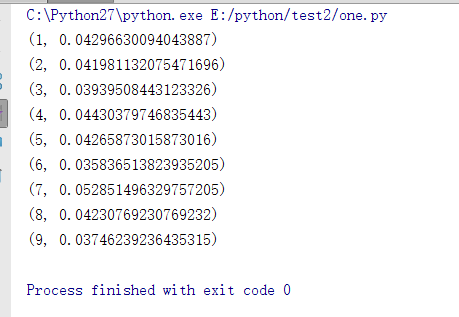
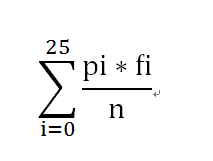 计算出M0,然后对子密文段移位25次,同样按照上述方法求出M1 — M25的值,
计算出M0,然后对子密文段移位25次,同样按照上述方法求出M1 — M25的值,